
Required metadata for content tracking
Altmetric collects certain meta tags from the source code of a research output webpage, in order to recognize the research output when it is mentioned or shared in one of the attention sources we track.
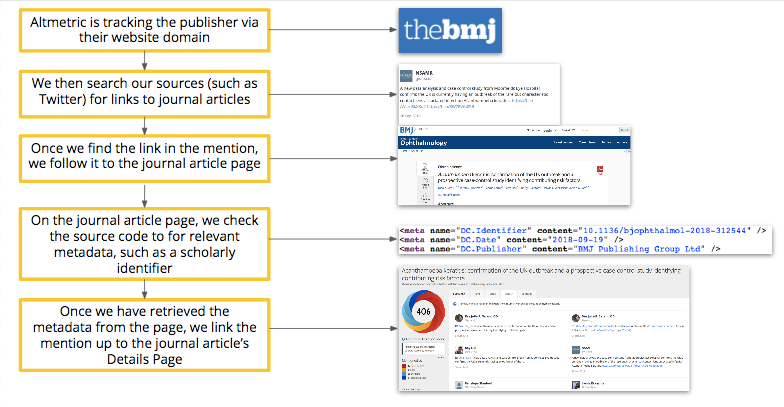
When a research output is mentioned in a source that Altmetric tracks, such as a policy document, our system visits the research output page to link up the attention. Altmetric looks at the source code of the research output page in order to collect the relevant metadata needed to identify the research output.
What metadata should be included on the research output page?
Altmetric's minimum metadata requirement is two of the supported meta tags listed in the table below, one of which must be a registered unique scholarly identifier (the only exception to this are journal articles that have a Crossref-registered DOI - see this page for more detail). This will enable us to associate attention to the correct research output.
We recommend adding at least the following meta tags for all research outputs:
Identifier (e.g., <citation_doi>) - required; one of the meta tags must include a unique identifier.
Title (e.g., <citation_title>)
Author (e.g., <citation_author>)
ISSN - if applicable (e.g., <citation_issn>)
More metadata is better! More detailed metadata improves the bibliographic information for the record of your research held in the Altmetric database, and enhances the online visibility across search indexes and services such as Google Scholar.
We recommend adding as many of the supported meta tags listed in the table below as possible (one meta tag per value is preferred).
Crossref-Registered DOIs
For journal articles with a Crossref-registered DOI, you only need to have the DOI meta tag in the source code. The rest of the metadata, such as title or publication date, will be retrieved directly from the Crossref API (more information on how we do this is available here).
Here’s an example of the meta tag you could use to display your DOI:
Identifier (e.g., <meta name="DC.Identifier" content="10.1136/bmj.k3845" /> )
Supported metadata tags
Please note that all tag names are not case sensitive and we only require one tag per value.
Value | Meta tags |
DOI (unique identifier) |
|
PubMed ID (unique identifier) |
|
arXiv ID (unique identifier) |
|
SSRNs (unique identifier) |
|
Authors |
|
Article title |
|
ISSN |
|
Journal title |
|
Journal issue |
|
Journal volumes |
|
Publishers |
|
Publication dates |
|
PDF URLs |
|
Step-by-step guide for assessing your metadata
On a journal article or other research output, view the source code for the webpage. (Usually accessible by right-clicking anywhere on the page and selecting "View Page Source" or similar.)
Look or search (via cmd/ctrl+f) for the meta tags that we support (see table above).
Determine if at least two pieces of metadata listed in the table above are visible on the page (one of these must be an identifier such as DOI, PubMed ID or arXiv ID) OR, if the output is a journal article, determine if there is a Crossref-registered DOI in the metadata.
Example
In the example below for an article published in Nature, we can see several of the meta tags that Altmetric requires in the source code of the page. This includes DC.identifier (with the DOI), DC.title, DC.creator, citation_title and citation_online_date.

When research outputs hosted on nature.com are mentioned or shared in one of the attention sources we track, we follow the links from the mention and use the meta tags we find on the research output page to match the mention with the corresponding research output.
Single page applications
For websites that are built using frameworks such as AngularJS and ReactJS, there can be issues with the visibility of meta tags for our scrapers. The reason for this is that these frameworks often render pages on the client side and so are not visible to our scraper at the point of making the request.
Without some additional configuration to your website, this would mean we would be unable to identify the research output being mentioned and ultimately unable to track any attention.
If you are planning to implement badges or you are adding metadata tags to allow tracking within a SPA, it is important to ensure that our required meta tags are visible within the page's metadata. One way to do this is to implement redirect rules to forward our user agent to a robot-only page where the metadata can be accessed. This is a common technique used by search engines to access metadata that is not visible within a page's HTML source code.